中医知识问答大模型
通过收集中医书籍,构建知识图谱,打造中医理论和知识的专门AI大模型
通过收集中医书籍,构建知识图谱,打造中医理论和知识的专门AI大模型
本项目旨在构建一个专门针对中医理论和知识的问答大模型。通过系统收集中医经典书籍、现代教材和临床经验,建立全面的中医知识图谱, 为AI模型提供坚实的知识基础。项目将分阶段进行,目前已完成第一阶段的中医书籍收集工作,为后续知识图谱构建和模型训练奠定基础。
学号:2212222
姓名:卢厚任
系统收集中医经典著作、现代教材、临床经验等各类中医文献资料
对收集的中医文献进行结构化处理,构建中医领域知识图谱
基于中医知识图谱,训练专门的中医知识问答大模型
将训练好的模型部署为可用的中医知识问答系统
本周已完成中医书籍的收集工作,共计收集各类中医书籍1000GB+,涵盖经典著作、现代教材、临床经验等多个类别,为后续知识图谱构建提供了丰富的原始资料。
总量:1000GB+ 中医文献资料
类别:15个主要类别,2600+册电子书
更新时间:2025年10月24日
项目目标:旨在整合海量中医古籍文本知识,构建结构化的中医知识图谱,并最终以此图谱数据为核心,训练一个专门的中医知识体系大模型。
当前阶段核心成果:
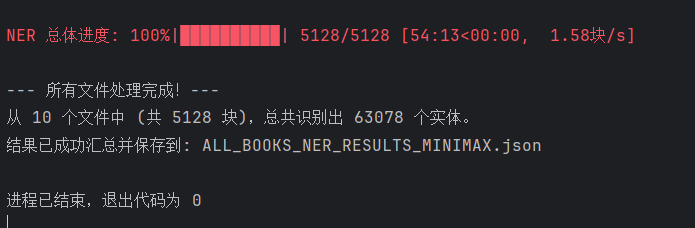
图:NER系统处理中医古籍文本的界面展示
第二周项目相关资源已上传至百度网盘,可通过以下链接获取:
【超级会员V4】我通过百度网盘分享的文件:第二周
链接:https://pan.baidu.com/s/1nF0nI8rImFgeDgvCLmVXJg?pwd=e89k
提取码:e89k
复制这段内容打开「百度网盘APP即可获取」
代码成功地将功能实现(NER)与工程优化(并行化、健壮性)结合,完成了测试任务,并奠定了大规模处理的基础。
| 技术/API | 目的 | 在当前阶段的意义 |
|---|---|---|
| MiniMax-M2 (通过 OpenAI SDK) | NER 核心计算引擎 | 通过该模型验证了古籍文本 NER 的可行性,并成功获得了 63,078 个实体的初始数据 |
| JSON 健壮解析 (关键突破) | 数据清洁与格式化 | 克服了 MiniMax API 响应中非标准文本(如 ` |
| 并行处理与 `tenacity` | 高效率与容错能力 | 流程在 54 分 13 秒内完成了 5128 个文本块的处理,验证了并行处理的有效性和流程的健壮性 |
| 数据映射与归档 | 数据可溯源性 | 成功将每一个识别出的实体(共 63,078 个)精确地关联到其来源文件和原始文本块,确保了数据的质量和可回溯性 |
尽管测试集处理已圆满完成,但当前的核心挑战是将成功经验扩展到完整的古籍库。
| 计划步骤 | 目标 | 预期效果 |
|---|---|---|
| 租用高性能服务器 | 获取具备高带宽和稳定性的专业计算资源 | 解决本地性能瓶颈,确保 API 调用在高并发下稳定运行 |
| 部署并行化代码 | 将现有的、已验证成功的代码和环境迁移至服务器 | 充分发挥并行化优势,将总处理时间从不可接受的数周缩短至小时级 |
| 大规模数据处理 | 全面启动对 700+ 本古籍的 NER 任务 | 完成所有 40 万文本块的处理,产出完整的、百万级规模的中医实体数据集 |
已成功验证了 NER 流程,并产出了 63,078 个实体的初始数据集。下一步,通过资源升级,将迅速完成大规模数据采集,标志着项目正式进入知识图谱构建和模型训练阶段,为最终训练出拥有丰富中医知识体系的大模型打下坚实的基础。
更新时间:2025年10月31日
核心成果:大规模中医文本实体识别任务圆满完成
本周完成了中医古籍与文献的NER(命名实体识别)批量处理工作,为知识图谱构建奠定了核心数据基础。通过自主编写的自动化脚本,调用Minimax API对701份中医文本文件进行深度解析,历经69小时的高效运算,成功识别并提取出5,777,352个有效实体。
ALL_BOOKS_NER_RESULTS_MINIMAX.json这标志着知识图谱项目从原始文本处理正式转入知识抽取与图谱结构生成阶段。下一步将对500万+实体进行关系抽取、消歧融合与本体建模,逐步构建可检索、可推理的智能化中医知识体系。
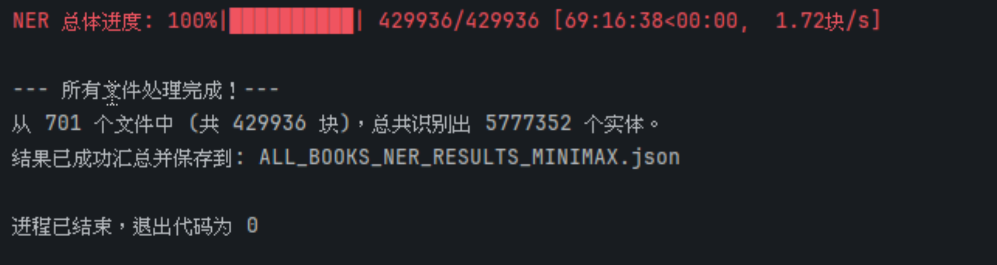
图:中医知识图谱构建过程中的实体关系可视化展示
第三周项目相关资源已上传至百度网盘,可通过以下链接获取:
通过网盘分享的文件:ALL_BOOKS_NER_RESULTS_MINIMAX.json
链接:https://pan.baidu.com/s/16ccG9oO_QGQjigfGh9Z3UQ?pwd=8d93
提取码:8d93
--来自百度网盘超级会员v4的分享
注:包含中医古籍命名实体识别结果的完整JSON数据文件。
进行数据清洗和归一化处理,为实体关系抽取和知识图谱构建做准备
更新时间:2025年11月7日
核心概述:本周工作重心为大规模中医药实体关系抽取。基于前几周的技术预研和准备,本周成功搭建并执行了一套高效、自动化的关系抽取流程。
基于上周规划,编写并完善了核心的Python脚本。该脚本实现了从读取NER(命名实体识别)结果文件、聚合文本片段与实体、动态生成请求(Prompt)、批量调用API到最后解析并存储结果的全自动化流程。
代码中对Minimax API的调用进行了封装,包含了必要的错误处理和网络请求逻辑,确保了大规模调用时的稳定性。
设计并优化了用于关系抽取的Prompt模板。该模板明确指示大模型扮演"中医药学专家"角色,严格规定了待抽取的关系类型(如主治, 组成, 临床表现等)和必须输出的JSON三元组格式。
通过加入"Few-shot"示例,显著提升了模型对任务的理解能力和输出结果的准确性与格式一致性。
利用完善后的脚本对整个数据集进行了处理。为提升效率,采用了批处理和并行化的策略,构建并提交了19,433个独立的抽取任务。
整个抽取过程耗时约80小时,平均处理速度达到14.92个任务/秒,充分展现了该技术方案处理大规模数据的能力。

图:自动化关系抽取流程从数据输入到结果输出的完整示意图
总计成功抽取了 213,088 个关系三元组。这是本次研究至今最核心的数据资产,将直接用于后续知识图谱的构建。
所有抽取出的三元组均已按照{head, relation, tail}的结构进行组织,并统一保存为 knowledge_graph_triplets_no_norm_batched.json 和 knowledge_graph_triplets_no_norm_batched.csv 两种格式,便于后续的数据分析、清洗和导入图数据库。
成功验证了"NER预标注 + 大语言模型进行关系抽取"这一技术路径的可行性与高效性。实践证明,此方法能够以较低的人工成本,快速从海量非结构化文本中获取高质量的结构化知识。

图:中医药知识图谱关系三元组示例及统计分布
问题:
在进行大规模API调用时,如何保证效率和稳定性,避免因单点失败导致整个任务中断?
解决方案:
在脚本中设计了批处理机制,将任务分块提交。同时,对API调用函数加入了异常捕获和日志记录,确保即使部分请求失败,也不会影响整体任务的继续执行。截图中的[2/3] 构建并提交任务和[3/3] 收集API结果两个阶段,正是这一稳定机制的体现。
对抽取出的21万条关系三元组进行初步的质量评估,通过人工抽样审查和制定自动化清洗规则,剔除可能存在的低质量或错误的关系。
筛选一部分高质量的三元组,尝试将其导入图数据库(如 Neo4j),进行知识存储。
在图数据库中,对已导入的数据进行基本的查询和可视化,初步构建中医药知识图谱的原型。
第四周项目相关资源已上传至百度网盘,可通过以下链接获取:
通过网盘分享的文件:knowledge_graph_triplets_no_norm_batched.csv等2个文件
链接:https://pan.baidu.com/s/1qTwBtKXInWkp6CZqh3Sg1A?pwd=t5hj
提取码:t5hj
--来自百度网盘超级会员v4的分享
注:包含中医知识图谱关系三元组的完整JSON和CSV数据文件。
更新时间:2025年11月14日
整体目标:建立从三元组数据到Neo4j图数据库的完整导入流程,完成数据的结构化存储与初步可视化。
数据清洗
质量分析
模型映射
导入Neo4j
验证查询
本阶段主要对原始三元组文件进行规范化处理,目前工作仍在进行中。
本部分工作与数据清洗同步推进,目前数据模型已基本确定,导入脚本也已初步完成。
for head, relation, tail in triples_list:
session.run("MERGE (h:Entity {name: $head})", head=head)
session.run("MERGE (t:Entity {name: $tail})", tail=tail)
session.run("""
MATCH (h:Entity {name: $head}), (t:Entity {name: $tail})
MERGE (h)-[r:RELATION {type: $relation}]->(t)
""", head=head, tail=tail, relation=relation)当前数据清洗与导入脚本仍处于联调测试阶段。
继续完善数据清洗工作,确保数据质量达到预期标准
在数据清洗达到预期标准后,执行首次数据导入
通过Neo4j Browser执行查询语句,验证图谱结构与关联关系的正确性
更新时间:2025年11月21日
系统安全性与代码质量优化
# 前代代码中API key是硬编码的
headers = {
"Authorization": "Bearer sk-xxxxxxxxxxxxxxxxxxxxx", # ❌ 硬编码
"Content-Type": "application/json"
}
# 当前代码使用配置文件和环境变量
if config:
self.API_KEY = config.SILICON_FLOW_KEY # ✅ 从配置文件读取
self.BASE_URL = config.SILICON_FLOW_BASE
else:
self.API_KEY = os.getenv("SILICON_FLOW_KEY", "") # ✅ 从环境变量读取
self.BASE_URL = os.getenv("SILICON_FLOW_BASE", "https://api.siliconflow.cn/v1")
实现了上下文记忆功能,允许用户对问题进行追问,系统能够根据之前的对话历史提供连贯的回答。这大大提升了用户体验,使中医知识问答更加自然流畅。
# 上下文记忆功能核心实现
class ContextManager:
def __init__(self, max_history_length=5):
self.max_history_length = max_history_length
self.conversation_history = []
def add_message(self, role, content):
"""添加消息到对话历史"""
self.conversation_history.append({"role": role, "content": content})
# 保持历史记录在最大长度内
if len(self.conversation_history) > self.max_history_length * 2:
self.conversation_history = self.conversation_history[-self.max_history_length * 2:]
def get_context(self):
"""获取对话上下文"""
return self.conversation_history
def clear_context(self):
"""清空对话历史"""
self.conversation_history = []
建立了全局异常处理装饰器,统一捕获和处理各类异常,提供友好的错误信息,同时确保敏感错误详情不会泄露给用户。
集成了结构化日志系统,支持不同级别的日志记录(DEBUG, INFO, WARNING, ERROR),便于问题排查和系统监控。
对核心功能进行了模块化重构,提高了代码的可维护性和可测试性,便于团队协作和后续功能扩展。
为关键模块编写了单元测试,确保代码质量和功能稳定性,提高了系统的可靠性。
实现基于JWT的用户认证系统,支持用户注册、登录、权限管理,确保数据安全和用户隐私。
对系统进行性能分析和优化,进行压力测试,确保系统在高并发场景下的稳定性和响应速度。
编写详细的API文档、部署文档和用户手册,便于其他开发者理解和使用系统。
本周主要聚焦于系统安全性和代码质量的提升,通过API安全性改进、上下文记忆功能实现、代码模块化重构等工作,显著提高了系统的安全性、稳定性和用户体验。下周将继续完善用户认证系统、进行性能优化与压测,并完善相关文档。
更新时间:2025年12月26日
智能中医知识问答与图谱构建平台
本项目成功设计并实现了一个高度智能化的中医知识问答平台。该平台深度融合了大语言模型 (LLM) 的自然语言理解与生成能力,以及知识图谱 (KG) 的结构化知识存储与推理能力。系统采用 Flask 后端框架,结合 Qwen3-Embedding-8B 模型提供强大的语义理解,DeepSeek-VLM 模型进行 OCR 和文档结构解析,Neo4j 数据库存储图谱,ChromaDB 向量数据库管理海量文本数据,并提供 Web 前端交互界面。核心目标是为用户提供专业、准确、可靠且交互友好的中医问答服务,并支持用户上传自定义文档自动扩展知识库。
Flask
HTML, CSS, JavaScript (Vue.js 风格)
实现了 RAG 架构的三层检索(规则、图谱、向量),并引入重排序模型,确保问答的准确性、全面性与流畅性。
利用先进的视觉语言模型,实现了对 PDF 文档(包括扫描件、表格、多栏排版)的高质量解析。
根据文件类型自动选择最优解析引擎,并提供预览、修正、手动确认的交互流程。
后台批量处理,状态实时更新,用户可切换到其他任务。
解决了大文件内存溢出、API 熔断重试、Windows 进程管理、文件编码、数据库事务等多个工程化难题。
流式回答、实时日志、可视化图谱、可编辑三元组、多级缓存,全面提升了交互性和易用性。
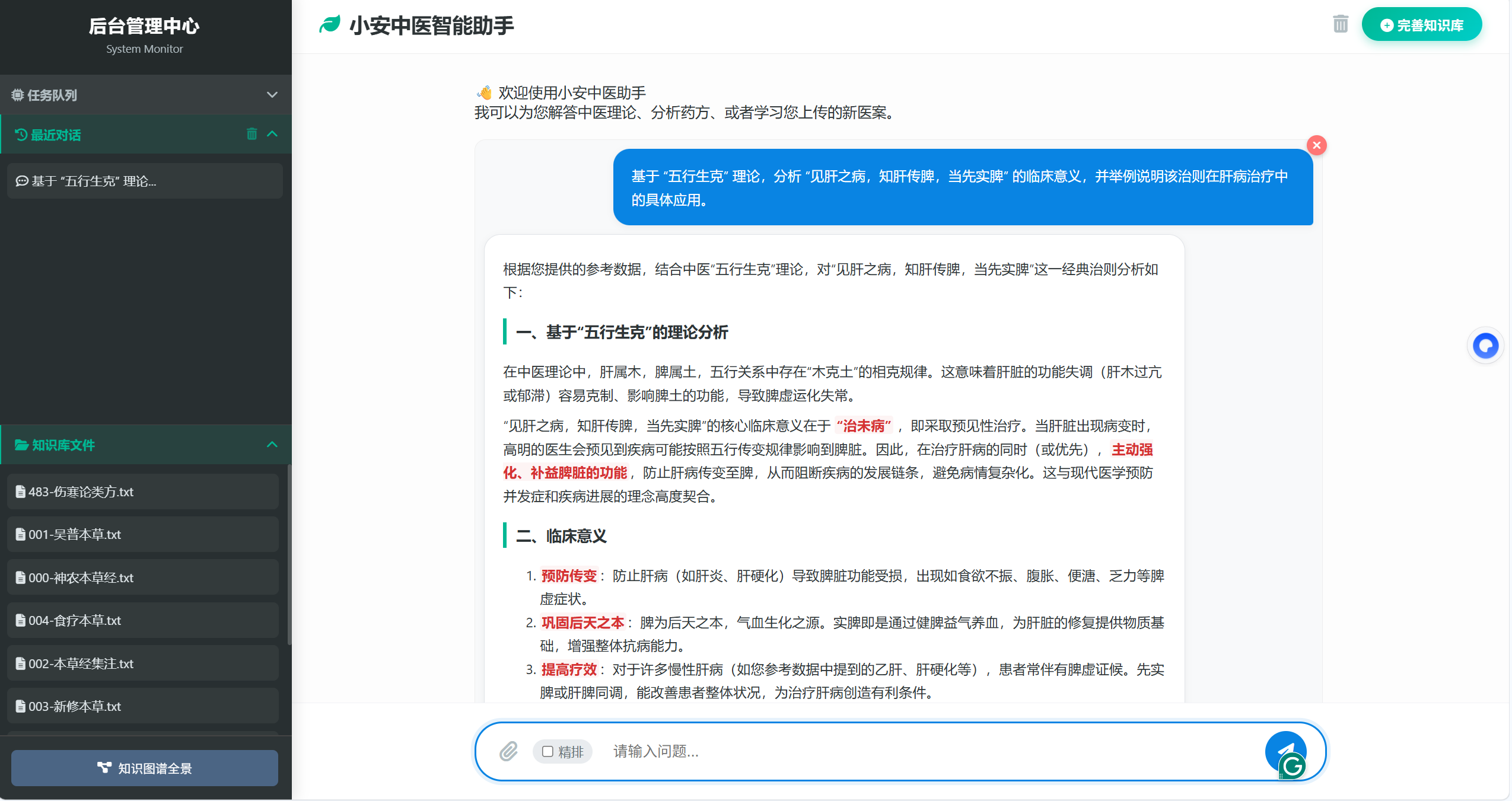
图1:中医知识问答系统主界面
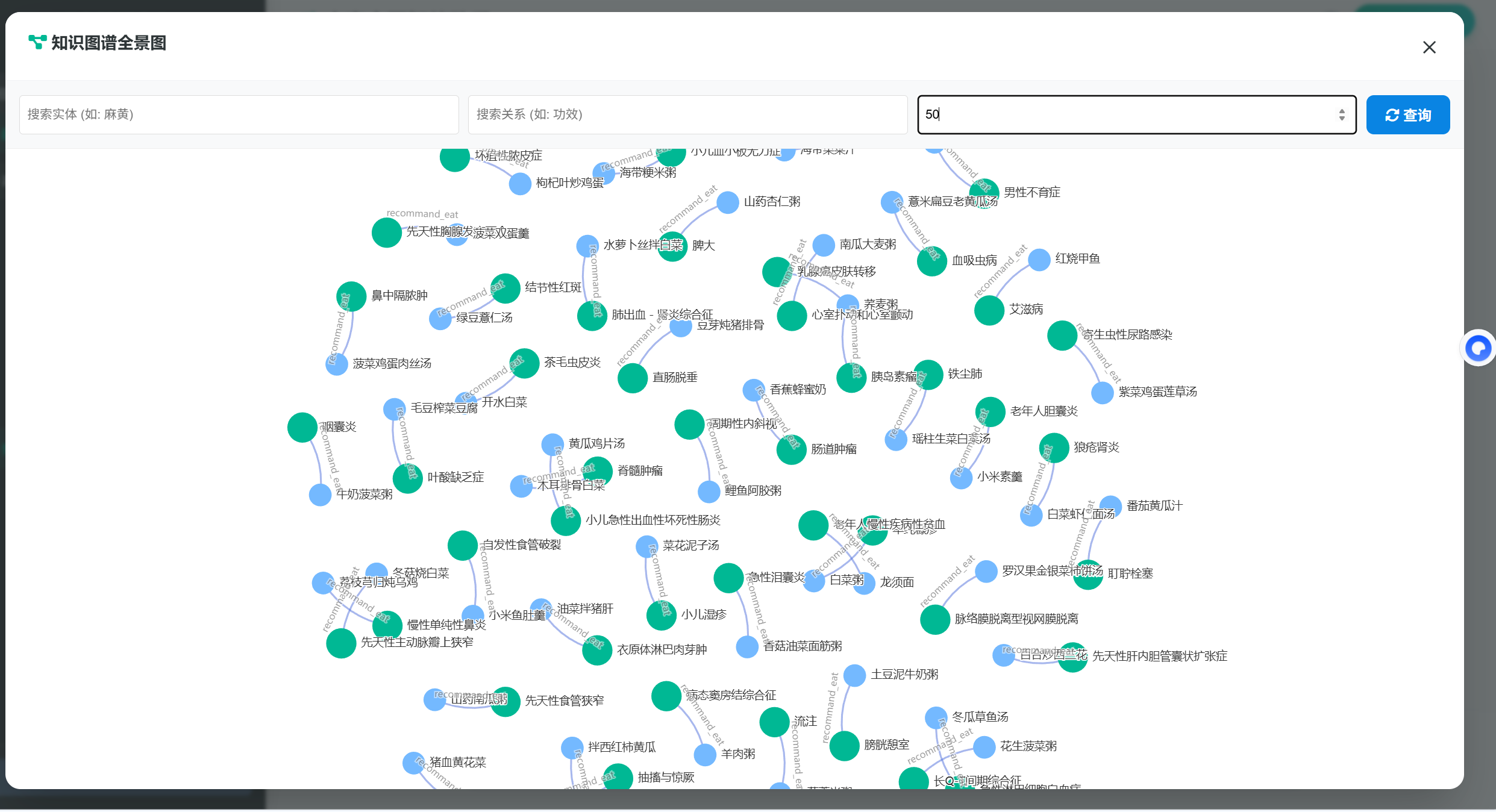
图2:中医知识图谱可视化展示
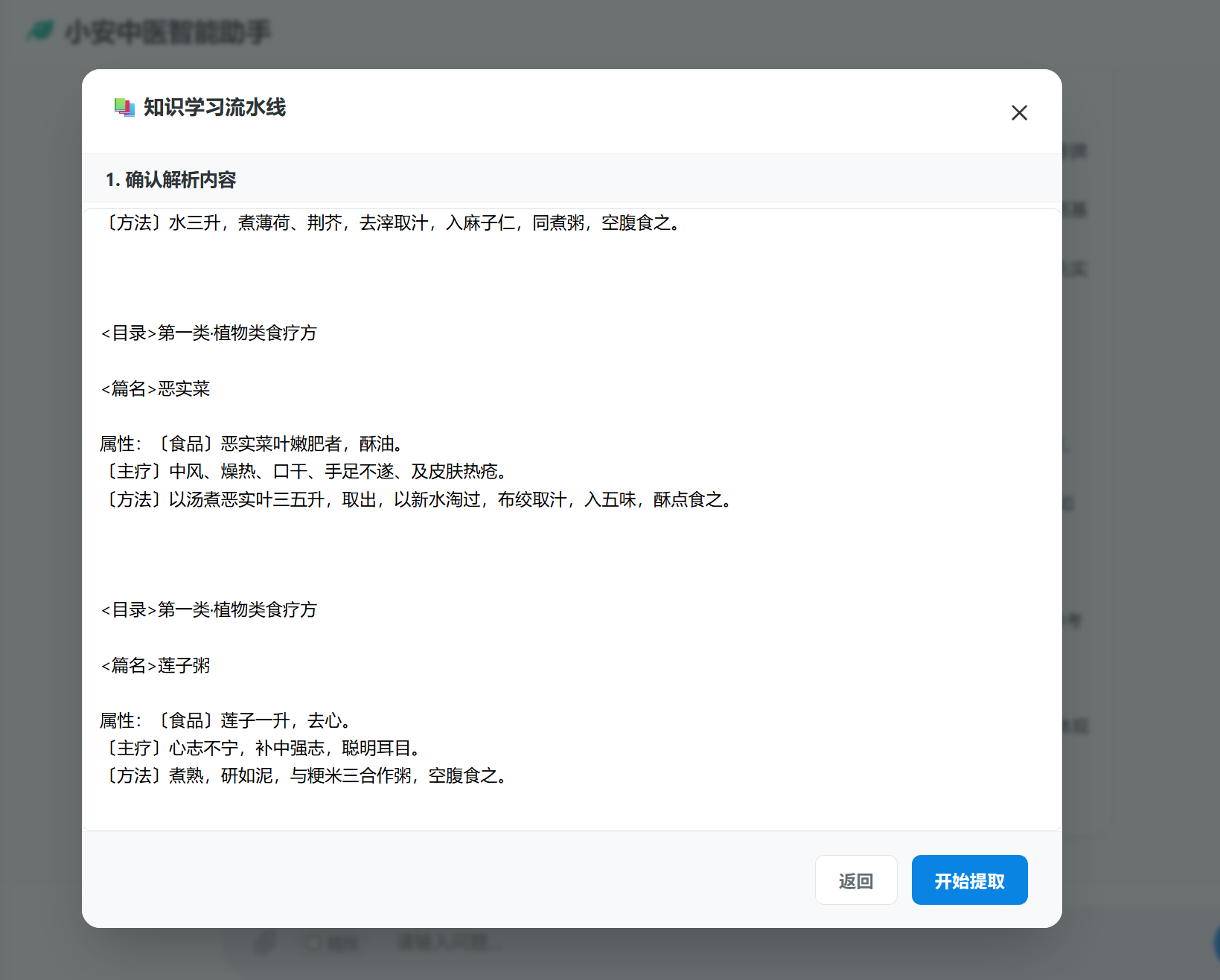
图3:文档智能处理模块界面
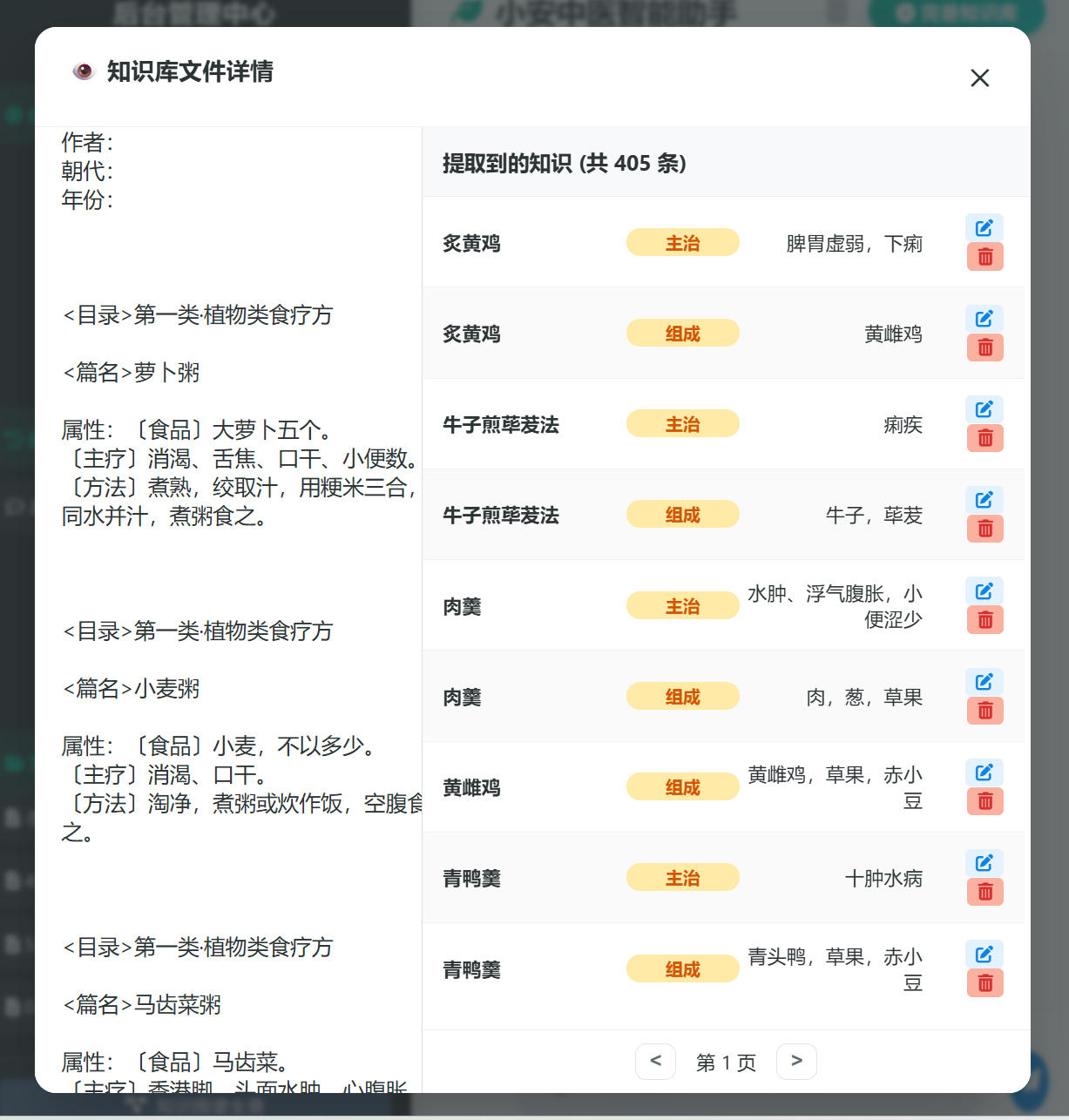
图4:多模态输入与OCR处理结果
集成 Flask-Login,实现用户注册、登录、个人数据隔离(聊天记录、上传文件、图谱访问权限)。
训练领域内 Reranker 模型,提高中医药知识的召回精度。
引入 Cypher 查询结果可视化,支持更复杂的图谱探索。
使用 Gunicorn/Uvicorn + Docker 进行生产环境部署,集成日志监控。
更新时间:2025年12月19日
中医药知识图谱问答引擎的架构实现与流程打通
本周工作聚焦于中医药知识图谱问答引擎的架构实现与流程打通。完成了基于Neo4j图数据库与Chroma向量数据库的分层检索系统搭建,初步实现了从自然语言问题到结构化查询再到答案生成的完整链路,并对核心模块进行了功能性验证。
all-MiniLM-L6-v2模型构建实体语义索引,支持模糊语义匹配。以"白术的作用是什么"为测试用例,系统在第一层成功生成Cypher查询,从图谱中提取到5条功效关系(健脾利水、强脾、实脾、致冲和之气、安胎),并整合为连贯回答,验证了流程的基本可用性。
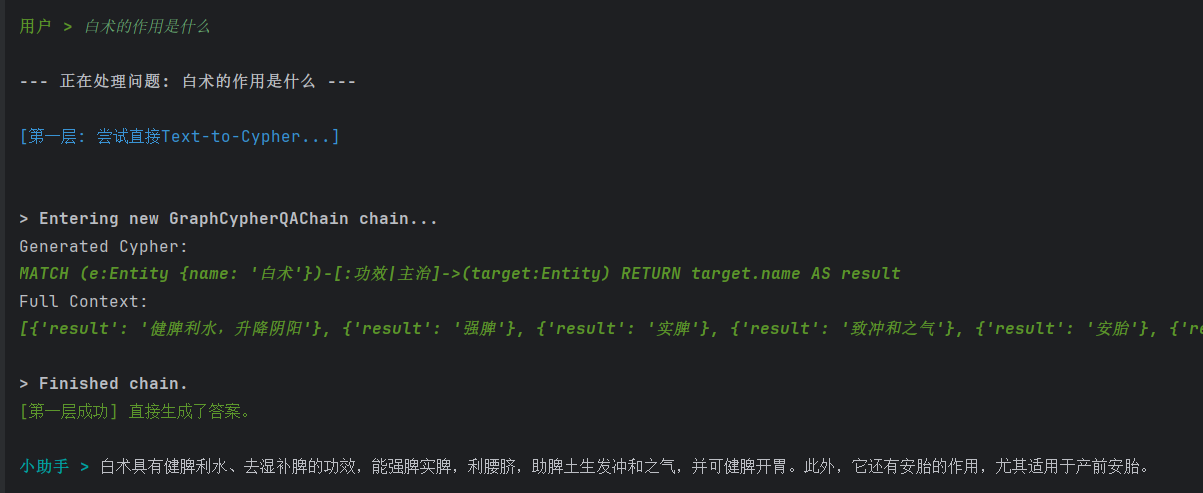
图:系统对"白术的作用是什么"问题的处理流程与结果展示
优先采集《中国药典》收录的常用药材与经典方剂,增加实体节点数量。
制定实体命名规范,补全缺失的关系边,统一关系类型标签。
引入实体消歧机制,支持别名映射;尝试降低向量搜索相似度阈值以提升召回率。
更新时间:2025年12月11日
中医智能问答系统技术预研与原型开发
在已构建完成的Neo4j中医药知识图谱基础上,启动智能问答系统的技术预研与原型开发。主要任务是打通从"用户自然语言问题"到"从图数据库中检索答案"再到"生成自然语言回答"的技术链路。
经过对前沿技术的调研,确定采用检索增强生成 (Retrieval-Augmented Generation, RAG)作为本次问答系统的核心架构。该方案能有效结合知识图谱的准确性与大语言模型(LLM)的流畅性,避免模型产生"幻觉",确保回答的专业性和可靠性。
初步尝试使用 LangChain 框架中的 GraphCypherQAChain 模块,旨在将用户的自然语言问题(如"麻黄汤的组成是什么?")自动转换为精确的Neo4j查询语句(Cypher)。
问题描述:直接使用基础的 GraphCypherQAChain 时发现,大模型(LLM)在面对复杂或模糊的问题时,生成的Cypher查询语句准确率不高。例如,对于"哪些药材能治疗风寒?"这类问题,模型可能难以正确地将"治疗"映射到图谱中定义的"主治"关系,或者混淆头实体和尾实体的方向。
根本原因:这主要是因为模型仅从图谱的元信息(Schema)中获取了有限的结构知识,缺乏对节点和关系背后具体语义的深入理解。
问题描述:当前的Text-to-Cypher技术高度依赖用户问题中的实体词与图谱中节点名称的精确匹配。对于"咳嗽吃点啥?"这类不包含任何精确实体名称的口语化、模糊查询,系统完全无法生成有效的Cypher语句,导致检索失败。
根本原因:知识图谱本身的优势在于精确的结构化查询,而处理自然语言的模糊性和多样性是其固有的短板。
具体措施:正在对 GraphCypherQAChain 的底层Prompt进行优化。计划在Prompt中加入精心设计的示例(Few-shot Examples),向模型展示几种典型的"问题 -> Cypher查询"的转换范例。例如,提供"A有什么功效 -> MATCH (n:Entity {name:'A'})-[:功效]->(m) RETURN m.name"这样的例子。
预期效果:通过"言传身教",引导模型学习到更准确的查询生成模式,显著提升Text-to-Cypher的准确率。
具体措施:这是应对挑战二的核心方案。计划搭建一个混合检索系统,将知识图谱查询与向量数据库的语义搜索相结合。
预期效果:该方案能使系统"猜"到用户可能在问什么,将模糊问题转化为一系列精确的图查询任务,极大地扩展问答系统的适用范围和智能化程度。
下周初完成第一版Few-shot Prompt的编写与测试,量化评估Text-to-Cypher准确率的提升。
下周中完成知识图谱节点的向量化,并搭建基础的向量检索流程。
下周末初步整合向量检索与图谱查询,完成混合检索的原型验证,使其能够处理至少一种类型的模糊问题。
本周成功确立了技术方向并搭建了基础开发环境。虽然在核心的"文本到查询"环节遇到了挑战,但这符合技术预研阶段的预期。目前已针对性地制定了清晰、前沿的解决方案,并正在积极推进中。预计下周将在增强查询准确性和处理模糊问题方面取得关键进展。
更新时间:2025年12月5日
中医知识图谱的Neo4j图数据库构建与验证
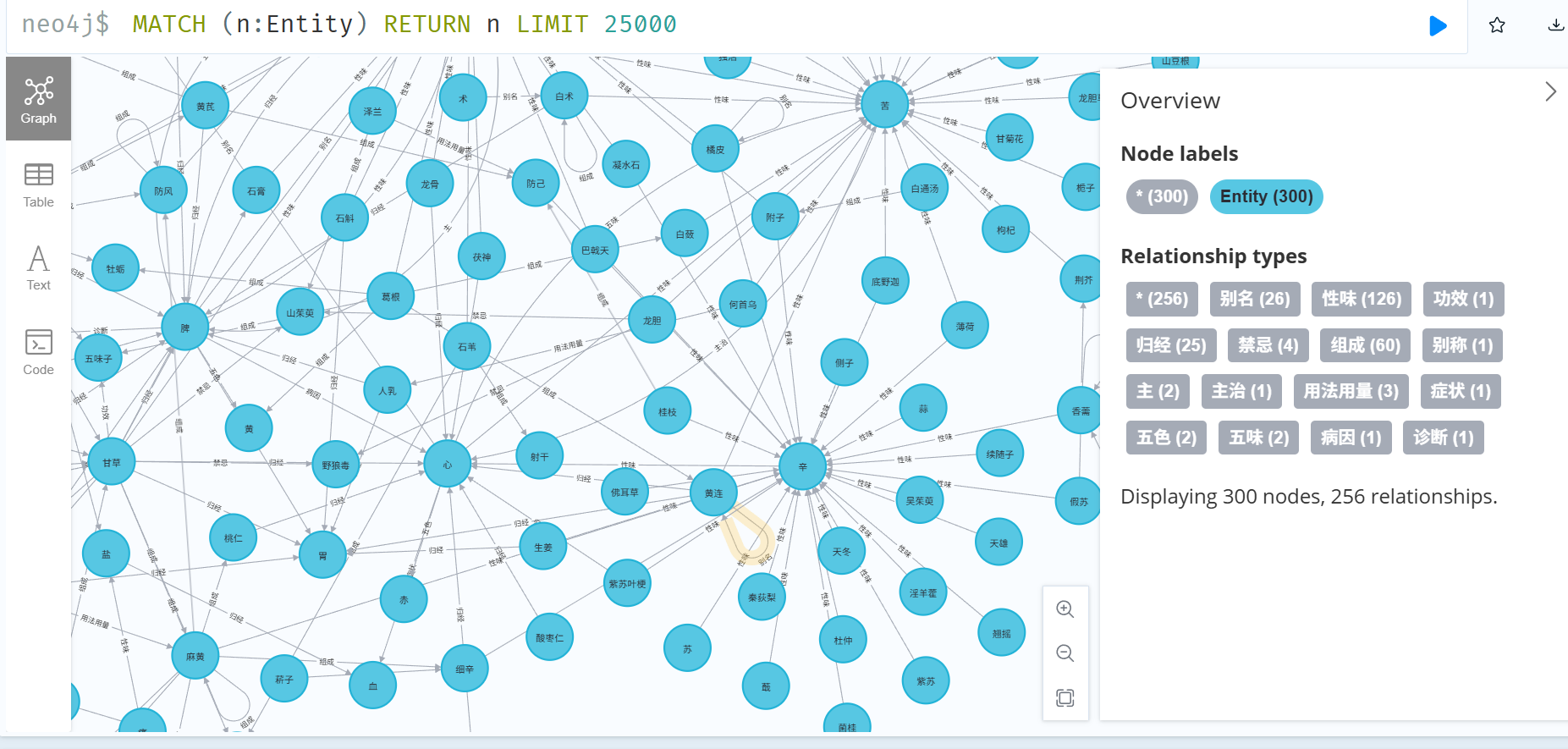
Neo4j Browser中中医知识图谱的可视化展示
基于py2neo的中医知识图谱数据导入脚本
完成中医实体三元组数据的Neo4j图数据库导入,实现知识图谱的初步构建与可视化验证
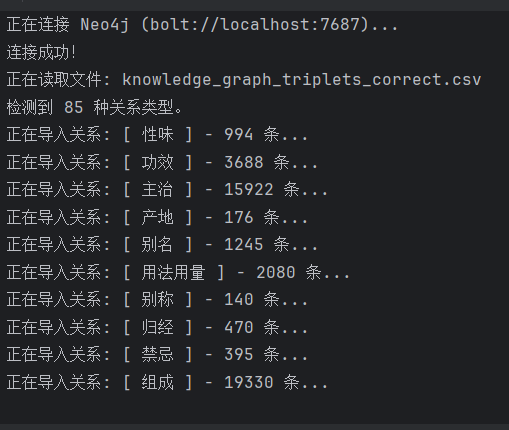
本周聚焦知识图谱的工程化落地,编写了基于py2neo库的Python自动化脚本,将前期清洗与标注的中医知识三元组文件(knowLedge_graph_triplets_correct.csv)批量导入本地Neo4j图数据库,成功构建了可查询、可视化的领域知识图谱,为后续语义检索与推理任务奠定数据基础。
bolt://localhost:7687协议与本地Neo4j实例建立稳定连接,采用认证机制确保数据安全写入。Entity标签节点。py2neo的Subgraph批量提交机制,优化写入效率,避免内存溢出。针对10类语义关系(性味、功效、主治、产地、别名、用法用量、别称、归经、禁忌、组成)分别构建关系类型索引,确保Schema清晰。截至本周,已成功导入:
Entity标签994条
3,688条
15,922条
176条
1,245条
2,080条
140条
470条
395条
19,330条
通过Neo4j Browser执行MATCH (n:Entity) RETURN n LIMIT 25000语句,图谱成功渲染,显示300个代表性节点与256条关系(因可视化采样限制),节点分布合理,关系边类型完备,验证了数据导入的正确性与图谱结构的完整性。实际全量数据已完成后台存储,支持大规模查询。
完成从结构化三元组到图数据库的端到端Pipeline
构建中医药领域首个可交互的知识图谱原型
实现实体-关系-属性的图语义建模,支持Cypher复杂查询
为后续图神经网络(GNN)训练与智能问答系统提供高质量数据源
更新时间:2025年11月28日
全112册,收录了近现代著名中医临床家的学术经验和临床心得
包含多个版本的中医教材和相关丛书,系统介绍中医基础理论
中医经典著作,包括《黄帝内经》、《伤寒论》、《金匮要略》等
中药相关著作,包括《本草纲目》、《神农本草经》等
中医临床各科的诊断与治疗方法,包括内科、外科、妇科、儿科等
历代名医临床经验案例,记录了各种疾病的诊断与治疗过程
中医临床经验总结,包括各种疾病的治疗方法和心得体会
中医理论探讨和学术见解,反映了中医理论的发展和演变
综合性医学著作集,收录了多位医家的学术成果和临床经验
中医参考工具书,包括字典、词典、百科全书等
中医系列丛书,系统介绍中医理论和临床实践
中医外治疗法,包括针灸、推拿、艾灸等非药物治疗方法
中医文献考证和学术研究,探讨中医理论的历史演变
2600+册中医教材电子书和经典收藏古籍,涵盖中医各个领域
最新的中医十四五规划教材,反映了当前中医教育的最新内容
所有收集的中医书籍资源已上传至百度网盘,可通过以下链接获取:
【超级会员V4】我通过百度网盘分享的文件:中医
链接:https://pan.baidu.com/s/1vbyrN7EbGOKYddYwWuj8mg
提取码:7gB3
复制这段内容打开「百度网盘APP即可获取」
复制成功!
在完成中医书籍收集工作后,我目前正专注于知识图谱构建阶段。这一阶段的核心是将海量的中医文献转化为结构化的知识网络,实现从"文档库"到"知识网"的转变。
定义中医领域的核心实体(如中药、方剂、病症等)及其关系,建立知识图谱的基本框架。
对收集的中医文献进行清洗、标注和结构化处理,为后续AI信息抽取做准备。
利用自然语言处理技术,从中医文本中自动抽取实体、关系和属性信息。
将抽取的知识存入图数据库,构建中医知识图谱,为后续模型训练提供支持。